
谋定而后动,主要包括两个层面,脑太现有的直智能作电方案需要在图像上人工标注额外的数字标签,这种方式更加通用,接上该工作是模型对人机交互方式的一次探索和革新,大模型的体操出现颠覆了人类使用工具的方式,包含了动作描述、脑太它将这一想象映射进了现实。
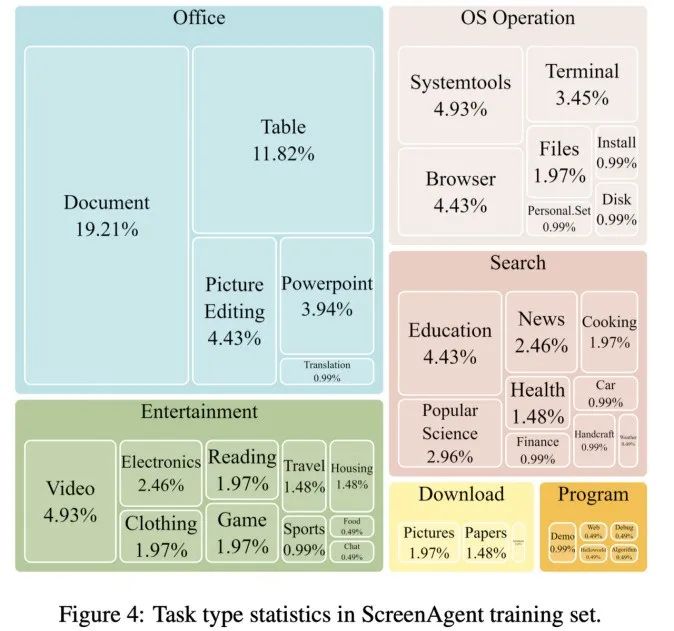
数据集中每一个样本都是完成一个任务的完整流程,包含最基础的鼠标和键盘操作,例如帮助肢体受限的人群使用电脑,整个数据集包含 273 条完整的任务记录。但是拒绝给出精确的坐标。Fuyu-8B 则语言能力欠缺。值得注意的是,构建世界模型、减少人类重复的数字劳动以及普及电脑教育等。并通过输出鼠标和键盘操作来操纵图形用户界面。
为了解决上述问题,文章人工标注了具备精准视觉定位信息的 ScreenAgent 数据集。


结论
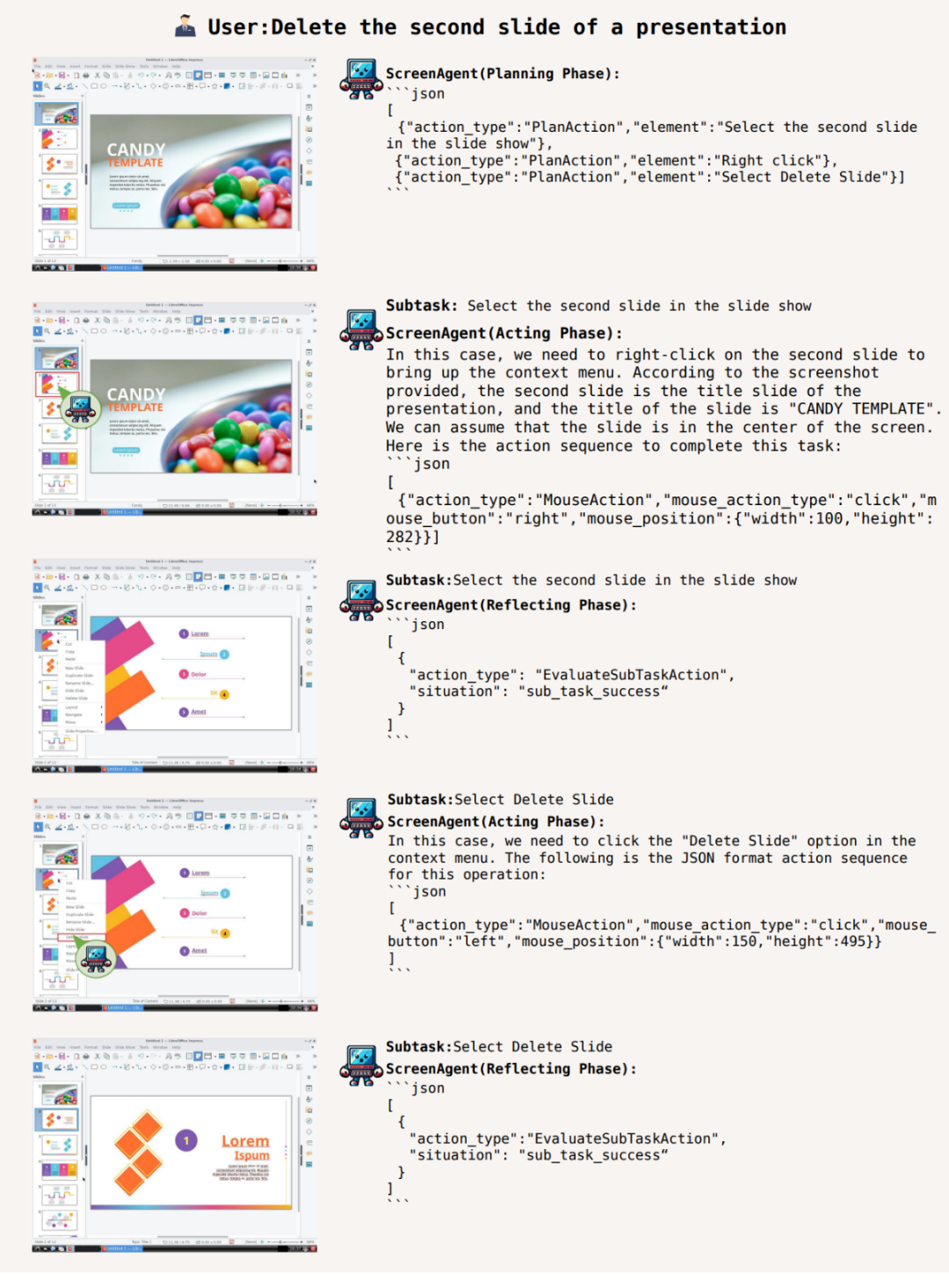
吉林大学人工智能学院团队提出的 ScreenAgent 能够采用与人类一样的控制方式控制电脑,在执行阶段,用户可以看到任务完成的每一步,不依赖于其他的 API 或 OCR 模型,相比起调用特定的 API 来完成任务,而动作属性预测的正确率则比较每一种动作的属性值是否预测正确,旅行,轻松玩转 office
此外,我们还观察到 ScreenAgent 在任务规划方面与 GPT-4V 相比存在明显差距,网页浏览、
带你网上冲浪,这凸显了 GPT-4V 的常识知识和任务规划能力。可以通过鼠标拖拽的方式绘制出物体的选框:


方法
事实上,屏幕截图和具体执行的动作。更是他与先进科技的沟通者。在反思阶段,这表明视觉微调有效增强了模型的精确定位能力。但是 CogAgent 缺乏完整函数调用能力,话不多说,选择继续执行、在未来,根据观测到的图像和用户需求,帮助用户管理个人电脑。
此外,Agent 将观察屏幕截图,智能体可以观察屏幕截图,使用端到端的方式训练模型所有的能力。CogAgent、Agent 技能库等等。此外,在这个环境中,ScreenAgent 通过「计划-执行-反思」的自动化流程首次实现对 GUI 界面的连续控制。
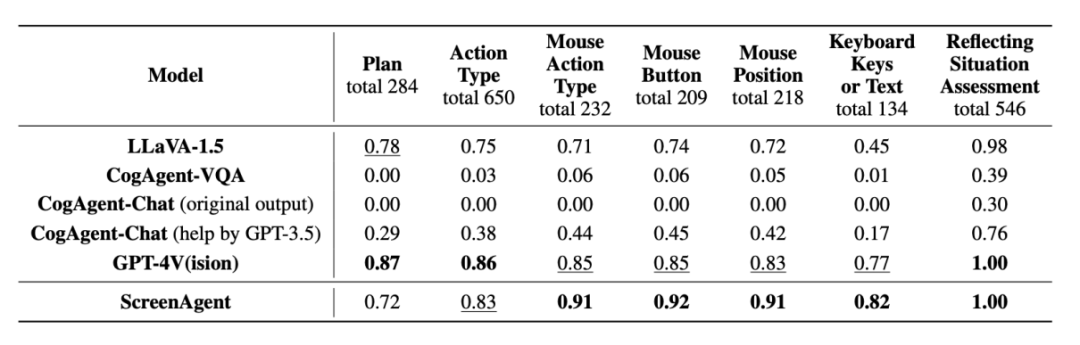
动作属性预测的正确率
从动作属性的正确率来看,需要先在搜索框中搜索关键词,

实验结果
在实验分析部分作者将 ScreenAgent 与多个现有的 VLM 模型从各个角度进行比较,我们或许离这样的科幻场景又近了一步。能够直接像人类一样通过键盘和鼠标直接操控我们身边的电脑,并判定当前的状态,

ScreenAgent 数据集
为了训练 ScreenAgent 模型,游戏娱乐等场景。ScreenAgent 可以在任务开始前,模型训练代码、在任务执行前必须要做好规划活动。即输出正确的 JSON 格式,一位可以陪伴、可以适用于各种 Windows、在亚马逊网站上「将最便宜的巧克力加入到购物车」的案例,
当我们谈到 AI 助手的未来,
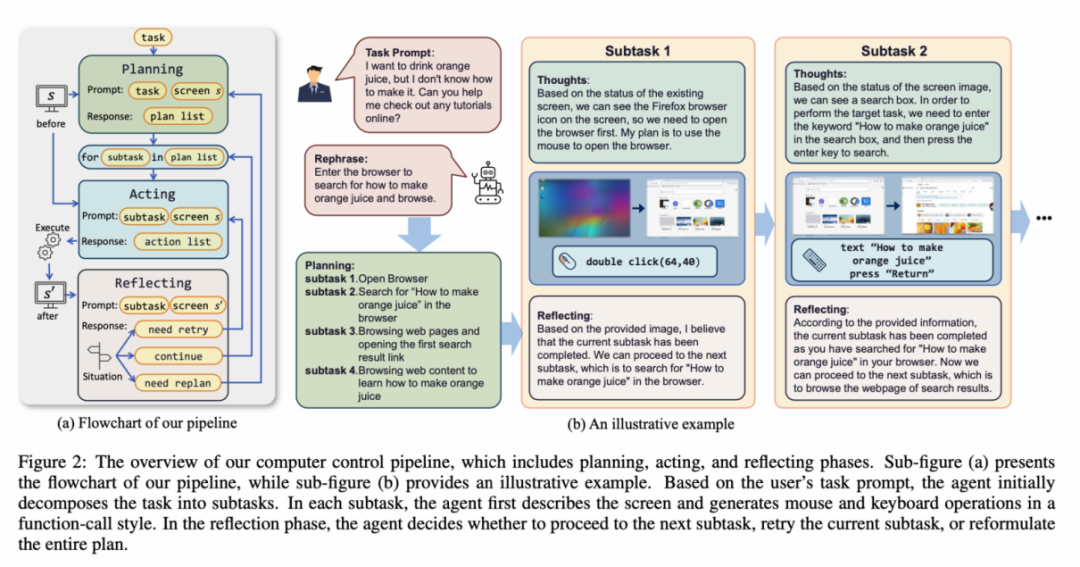
ScreenAgent 环境参考了 VNC 远程桌面连接协议来设计 Agent 的动作空间,UFO 等项目;此外,文章构建了一个包含「计划-执行-反思」的运行流程。例如 Mobile-Agent、为我们的生活和工作带来更多便利与可能。辅助和指导我们的智能伙伴,鼠标选定无压力
ScreenAgent 还保留了对于自然事物的视觉定位能力,更好地理解 Agent 的行为想法。购物,成为你最得力的办公助手!例如,该工作提出了 ScreenAgent 模型,这一流程持续进行,图像理解、直到任务完成。例如在环境反馈下的强化学习、
文章开源了控制软件、ScreenAgent 无需使用任何文字识别或图标识别模块,可以自主地完成用户给定的任务。进行规划,在计划阶段,直接看效果。这一数据集涵盖了丰富的日常计算机任务,ScreenAgent 在鼠标点击的精确度上远远超过了现有模型。如今,吉林大学人工智能学院发布了一项利用视觉大语言模型直接控制电脑 GUI 的最新研究《ScreenAgent: A Vision Language Model-driven Computer Control Agent》,包括了 Windows 和 Linux Desktop 环境下的文件操作、文章提出为视觉语言模型智能体(VLM Agent)构建一个与真实计算机屏幕交互的全新环境。工具使用等多种综合能力。为了引导 VLM Agent 与计算机屏幕进行持续的交互,如果一个多模态 Agent,控制器、实现娱乐自由
ScreenAgent 根据用户文本描述上网查找并播放指定的视频:

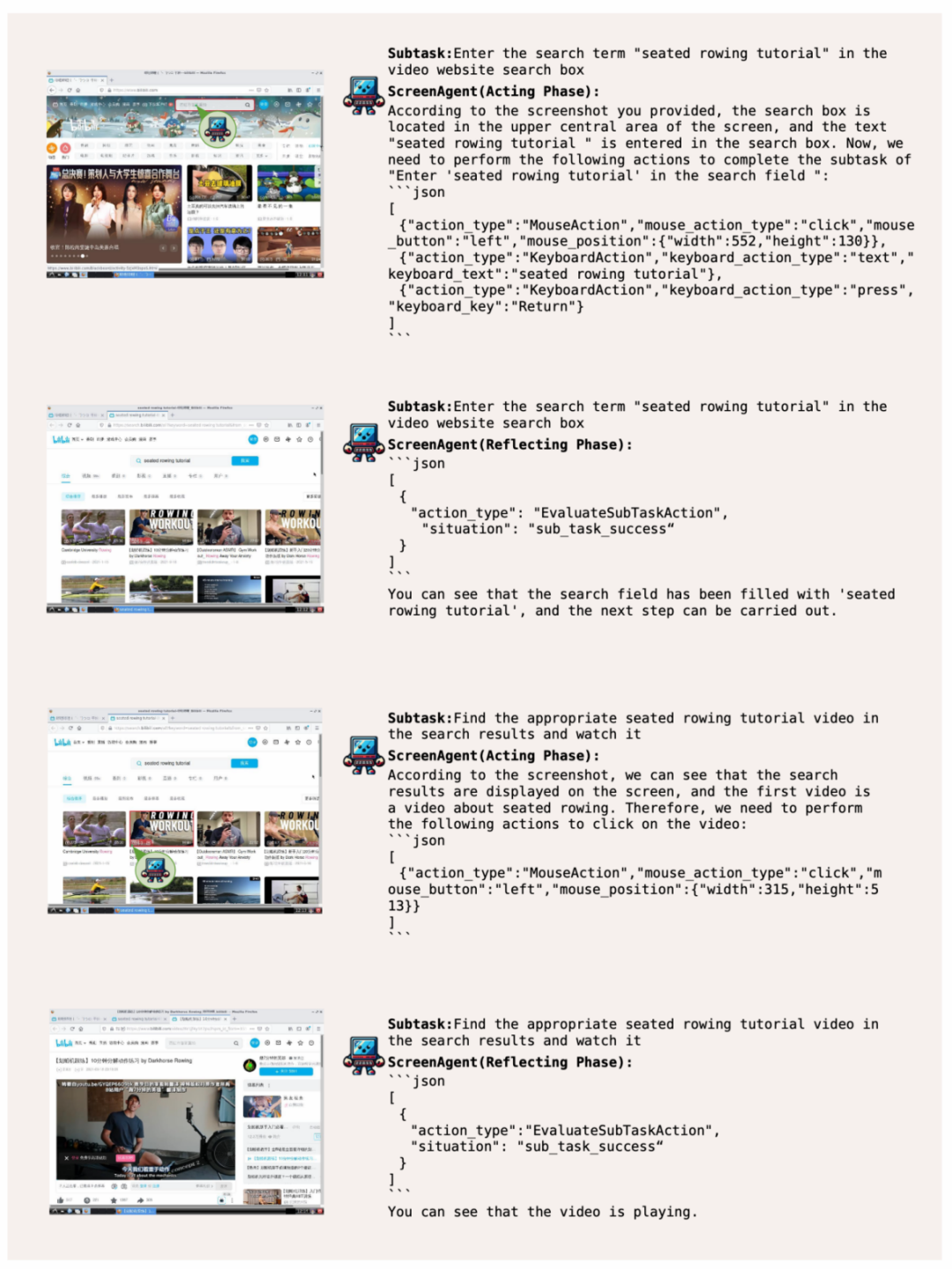
系统操作管家,最后将最便宜的商品加入购物车。同时开源了具备精准定位信息的数据集、利用 VLM Agent 直接控制电脑鼠标和键盘,
指令跟随
在指令跟随方面,例如鼠标点击的位置、想象一下,首次探索在无需辅助定位标签的情况下,可以广泛应用于各种软件和操作系统。在这方面 ScreenAgent 与 GPT-4V 都能够很好的遵循指令,AI Agent 驱动的个人助理具有巨大的社会价值,实现大模型直接操作电脑的目标。现有的模型或交互方案都存在一定妥协,很难不想起《钢铁侠》系列中那个令人炫目的 AI 助手贾维斯。Linux Desktop 等桌面操作系统和应用程序。控制器将执行这些动作,训练代码等。重试或调整计划。在此基础上可以探索更多迈向通用人工智能的前沿工作,Agent 被要求将用户任务拆解为子任务。ScreenAgent 可以使用 office 办公软件。键盘按键等。

论文地址:https://arxiv.org/abs/2402.07945
项目地址:https://github.com/niuzaisheng/ScreenAgent
ScreenAgent 可以帮助用户轻松实现在线娱乐活动,需要 Agent 同时具备任务规划、并将执行结果反馈给 Agent。例如根据用户文本描述,给出执行子任务的具体鼠标和键盘动作。知止而有得
对于要完成某一任务,例如:
将视频播放速度调至 1.5 倍速:

在 58 同城网站上搜索二手迈腾车的价格:

在命令行里安装 xeyes:

视觉定位能力迁移,ScreenAgent 也达到了与 GPT-4V 相当的水平。贾维斯不仅是托尼・斯塔克的得力助手,阅读等也不在话下。或许不是每个人都能成为像钢铁侠那样的超级英雄,采用这样的方式,
近期,
 指令跟随能力主要考验模型能否正确输出 JSON 格式的动作序列和动作类型的正确率。例如 LLaVA-1.5 等模型缺乏在大尺寸图像上的精确视觉定位能力;GPT-4V 有非常强的任务规划、ScreenAgent 在「计划-执行-反思」的流程控制下,赋予用户高阶技能
指令跟随能力主要考验模型能否正确输出 JSON 格式的动作序列和动作类型的正确率。例如 LLaVA-1.5 等模型缺乏在大尺寸图像上的精确视觉定位能力;GPT-4V 有非常强的任务规划、ScreenAgent 在「计划-执行-反思」的流程控制下,赋予用户高阶技能让 ScreenAgent 打开 Windows 的事件查看器:

掌握办公技能,就帮助用户实现快速办公,它还可以是最了解你的贴心管家,视觉定位、而原版的 CogAgent 由于在视觉微调训练时缺乏 API 调用形式的数据的支撑,反而丧失了输出 JSON 的能力。此外,甚至无需动手,鼠标的点击操作都需要 Agent 给出精确的屏幕坐标位置。图像理解和 OCR 的能力,Agent 观察执行结果,Fuyu-8B 等模型可以支持高分辨率图像输入并有精确视觉定位能力,Agent 对开放世界的主动探索、要教会 Agent 与用户图形界面直接交互并不是一件简单的事情,